Après avoir utilisé GIT en mission et migré mes projets perso, je vous propose un petit recueil de mes différentes lectures !
Créé par Linus Torvalds
en 2005, le père du noyau Linux, Git est aujourd'hui un système de contrôle de
version OpenSource à la mode. L’objectif d’un système de contrôle de version est de garder un historique de toutes
les modifications apportées aux fichiers d’un projet donné. Il est ainsi plus
aisé de savoir quel développeur a effectué une modification, quand il a
effectué, et surtout en quoi consistait cette modification. GIT est plus
particulièrement un outil de gestion de version décentralisé, cette
caractéristique signifie seulement que l’historique n’a pas nécessairement
besoin d’être stocké sur un serveur
central.
GIT n'était pas, au départ, à proprement parler un logiciel
de gestion de versions. Linus Torvalds expliquait que, « par bien des aspects, vous pouvez considérer Git comme un système de
fichiers : il permet un adressage associatif, et possède la notion de
versionnage, mais surtout, a été conçu en résolvant le problème du point de vue
d'un spécialiste des systèmes de fichiers. Il n'y avait donc aucun intérêt à
créer un système de gestion de version traditionnel. ». Il a aujourd'hui
évolué pour intégrer toutes les fonctionnalités d'un gestionnaire de versions.
GIT est aujourd'hui un
outil incontournable pour les développeurs, les architectes et les chefs de
projet qui collaborent sur le même code source. De nombreux outils tels qu’Eclipse
ou Netbeans l'intègrent par défaut ainsi que des plateformes de travail
collaboratif en ligne comme le réseau Github.com.
Concepts
clés à comprendre
Les systèmes de
contrôle de version centralisés comme Subversion ou CVS stockent pour chaque
fichier modifié, les modifications dans le temps. Il est important de noter que
GIT est très différent de ces systèmes. Subversion, CVS, et les autres
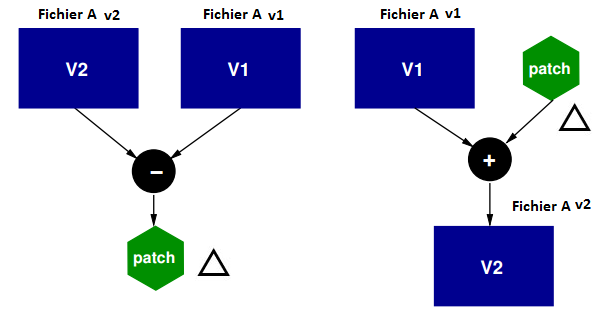
utilisent tous un système de stockage de Patch (∆) — ils stockent les
différences entre un commit et le suivant. Par exemple, le fichier de la
version 2 dans l’exemple ci-contre, est obtenu en appliquant le patch (∆) à la
version v1 du fichier (fichier A v2 = fichier A (v1) + ∆). Par contre, GIT stocke les
fichiers modifiés complets, et pas seulement les modifications (seulement s’ils
ont été modifiés). Ainsi pour obtenir la version 2, Git prend directement le
fichier v2.
Puisque GIT enregistre les modifications de manière globale au projet, la reconstruction de
l’historique d’un seul fichier demande plus de travail qu’avec un système de
gestion de versions (CVS par exemple)
qui traque les fichiers individuellement.
Objets manipulés par GIT
Il existe 4
types d’objet dans GIT. Chaque objet est caractérisé par 3 attributs : un type,
une taille et le contenu. La taille est simplement la
taille du contenu, le contenu dépend du type de l’objet et il y a 3 types
d’objets différents : « blob », « tree », « commit » :
• Un « blob » est utilisé
pour stocker les données d’un fichier — il s’agit en général d'un fichier.
• Un « tree » est comme un
répertoire — il référence une liste d’autres « tree » et/ou d’autres « blobs »
(i.e. fichiers et sous-répertoires).
• Un « commit » pointe
vers un unique "tree" et le marque afin de représenter le projet à un
certain point dans le temps. Il contient des méta-informations à propos de ce
point dans le temps, comme le timestamp, l’auteur du contenu depuis le dernier
commit, un pointeur vers le (ou les) dernier(s) commit(s), etc.
Il faudra
souligner que ces objets de types Blob,
Tree ou Commit ne sont pas mutables et ne doivent normalement pas être
supprimés. Dans la suite de cet article, nous allons détailler chaque type
d’objet.
Blob
Pour effectuer la
gestion des versions d’un projet, GIT dispose d’un répertoire spécifique
dénommé .git (nom par défaut). Le
répertoire .git contient tout
l’historique de GIT et les méta-informations du projet. Chacune des versions de
vos données est conservée dans la base d’objets (object database) qui
réside dans le sous-dossier .git/objects. GIT utilise un classement par contenu : les fichiers ne sont pas stockés selon
leur nom mais selon leur contenu. Ce contenu est stocké dans des fichiers du répertoire GIT (.git) dont le nom est déterminé avec l’empreinte des données qu’ils (les fichiers versionnés) contiennent. Nous pouvons considérer l’empreinte comme un ID
unique du contenu d’un fichier permettant de retrouver un fichier par son
contenu. L’empreinte est obtenue en appliquant une fonction de hachage.
Une fonction de hachage
est une fonction particulière qui, à partir d'une donnée fournie en entrée,
calcule une empreinte servant à identifier rapidement la donnée initiale. Les
fonctions de hachage servent à rendre plus rapide l'identification des données
: calculer l'empreinte d'une donnée ne doit coûter qu'un temps négligeable. Une
fonction de hachage doit par ailleurs éviter autant que possible les collisions
(états dans lesquels des données différentes ont une empreinte identique).
Pour chaque objet (un
fichier, un répertoire) modifié, GIT le stocke en appliquant :
-
La fonction de hachage SHA1 (sha1sum) pour pouvoir identifier ou
référencer (« référence » est à comprendre dans le même
sens qu'une « référence » Java, ou qu'un pointeur en C)
son contenu de façon unique. Cet identifiant est aussi utilisé comme nom du
fichier dans lequel le contenu compressé du fichier est sauvegardé
-
Une fonction de compression du contenu
du fichier (zlib) en données
binaires.
Le résultat de ces deux
opérations nous donne un blob :
Un « blob » n’est donc rien
de plus qu’un morceau de données binaires. Il ne fait référence à rien et n’a
aucun autre attribut excepté son type (Blob) et la taille, même pas un nom de
fichier. Puisque le « blob » est entièrement défini par son contenu, si deux
fichiers dans un répertoire (ou dans différentes versions du dépôt) ont le même
contenu, ils partageront alors le même objet blob.
Si par exemple le SHA de l'objet est ab04d884140f7b0cf8bbf86d6883869f16a46f65, alors le fichier sera stocké dans le chemin suivant :
.git/objects/ab/04d884140f7b0cf8bbf86d6883869f16a46f65
Il récupère les 2
premiers caractères (ab) et les utilisent comme sous-répertoire, comme
ça il n'y a jamais trop d'objets dans le même dossier. Le nom du fichier est
alors composé des 38 caractères restant.
La stratégie de
stockage des objets précédemment décrite peut devenir inefficace si par exemple
vous avez un fichier long de quelques milliers de lignes. Si une seule ligne
est modifiée, c’est un gaspillage si on se permet d’enregistrer un autre
fichier dans son intégrité (car les empreintes SHA1 seront différentes). Pour
pallier à ce problème, GIT ne sauve que la partie du fichier qui a été modifiée
dans un autre fichier avec un pointeur vers le fichier similaire (packfile).
Peut-être vous
demandez-vous ce qui se produit pour des fichiers ayant le même contenu.
Essayez en créant des copies de votre premier fichier, avec des noms
quelconques. Le contenu de .git/objects reste le même quel
que soit le nombre de copies que vous avez ajoutées. GIT ne stocke le contenu
qu’une seule fois.
Mais que deviennent les
noms des fichiers ? Ils doivent bien être stockés quelque part à un
moment. Pour répondre à la question, nous abordons le sujet d’un autre type
d’objet GIT appelé : tree.
Tree
L'objet tree (mot anglais signifiant « arbre »), est une liste d'objets de
type blobs ou d’autres tree et des
informations associées : le type (si c’est un fichier ou un répertoire),
le nom du fichier et les permissions, etc.
Il représente en général, le contenu d’un répertoire ou d’un sous-répertoire.
Un objet référencé par un « tree » peut être un « blob » représentant le
contenu d’un fichier ou un autre « tree » représentant le contenu d’un
sous-répertoire. Puisque les « trees » et les « blobs », comme les autres
objets, sont identifiés par le hash SHA1 de leur contenu, deux « trees » ont le
même identifiant SHA1 si, et seulement si, leur contenu (en incluant
récursivement le contenu de tous les sous-répertoires) est identique. Cela
permet à git de déterminer rapidement les différences entre deux objets « trees
» associés puisqu'il peut ignorer les entrées avec le même nom d’objet. Comme
le contenu d’un tree dépend de son contenu (ses fichiers et ses
répertoires), la question du sous
répertoire vide se pose. Comment stocker les sous répertoires vides ? La
réponse est claire, les sous répertoires vides ne peuvent pas être stockés.
Placez-y des fichiers sans intérêt pour remédier à ce problème.

Commit
Nous avons
expliqué 2 des 3 types d’objets. Le troisième est l’objet commit.
C’est un terme trompeur auquel je préfère le mot snapshot ou version d’un
projet. Par commit, nous entendons ici une version du repository, i.e. un état
(une photographie ou un snapshot) du projet à un instant donné. Le mot commit désigne à
la fois la création d'une nouvelle version (lorsque c'est un verbe) et cette
nouvelle version (lorsque c'est un nom). "Je commit" veut dire,
j'entérine les changements que j'ai effectués et ils constituent une version.
"Le deuxième commit de mon projet", désigne sa deuxième version. Notez qu’un «
commit » ne contient pas d’information à propos de ce qui a été modifié ; tous
les changements sont calculés en comparant les contenus du « tree » référencé
dans ce « commit » avec le « tree » associé au(x) parent(s) du « commit ».
A chaque fois que vous effectuez un
commit dans GIT, il prend effectivement une copie du contenu de votre espace de
travail à ce moment et enregistre une référence à cette copie. Si les fichiers
n’ont pas changé, GIT ne stocke pas le fichier à nouveau, juste une référence
vers le fichier original qui n’a pas été modifié. Quand on parle d’un commit
git, il faut systématiquement comprendre une version/snapshot du projet.
Un
commit est caractérisé par une référence à un commit parent (la version à
partir de laquelle, la nouvelle version du projet (commit) a été créée), un
auteur et un message qui décrit les modifications effectuées. Une autre
caractéristique d’un commit est la référence à un tree. Cette référence tree,
est une référence sur un répertoire contenant les objets du commit.
Vous pouvez voir que nous avons créé un objet tree pour chaque
répertoire (pour la racine aussi) et un objet blob pour chaque fichier.
Ensuite nous avons un objet commit qui pointe vers la racine, afin que
nous puissions récupérer l’apparence du projet quand il a été committé.
Comme évoqué
précédemment, un commit n’est ni plus ni moins qu’une version du projet, un
snapshot pris à un instant T. Partant d'un commit, disons A, on peut faire plusieurs
commits ayant comme parent ce commit A. C'est le cas dès que plusieurs
personnes font un commit en parallèle en partant de la même version.
A chaque fois que vous faites un commit,
GIT enregistre un «arbre» qui permettra d’identifier vos fichiers modifiés (qui
seront stockés sous forme de blobs) et lui associe un objet commit qui,
lui-même, pointera vers le (ou les) commit immédiatement précédent et la figure suivante en
donne un exemple :
Le commit v2 est créé à partir du commit
v1 qui lui aussi créé à partir de la version initiale v0. Vous pouvez constater
que des objets GIT sont partagés entre les commits. En effet, par exemple si le
contenu d’un fichier n’est pas modifié entre deux commits, son Blob reste
inchangée et sera référencé par les deux commits.
Branches
Dans le développement
d'un projet, il arrive souvent qu'on souhaite travailler sur une fonctionnalité
en limitant les interactions avec le reste de l'équipe. Un moyen de faire ceci
est d'utiliser ce qu’on appelle des branches. Une branche est une « ligne
de développement ». Les
branches permettent de séparer la version principale d’un projet, des versions
de travail, elles permettent également de travailler sur plusieurs
fonctionnalités de manière simultanée.
Vu qu'un commit n'est qu'une version du projet, il est tout naturellement possible de travailler su un commit. Lorsque vous connaissez la référence d’un
commit (disons C), vous pouvez effectuer un checkout afin de travailler sur
cette version du projet. Le développement démarre à partir du commit C et tous
vos futures commits formeront une branche dans l’arbre de commits du projet.
Cette arborescence de commits qu’on appelle une branche peut être identifiée
par un nom (le nom de la branche). Le nom est utilisé comme référence qui
pointe toujours vers le dernier commit de votre branche (la dernière version du
projet de votre branche). Une branche GIT est donc tout simplement un nom
donné à un commit. Lorsqu’un projet est initié pour être géré par GIT (git init), le tout premier commit crée automatiquement une
branche dénommée master (qu’on appelle la branche principale). A chaque commit
sur cette branche principale, la référence master se déplace et pointe sur le
dernier commit.
Comment
GIT connaît-il la branche sur laquelle vous vous trouvez ? Il conserve la référence
du dernier commit de la branche lors du checkout et lui donne un nom spécifique
HEAD. Comme le nom de votre branche qui pointe vers la référence du dernier
commit, le HEAD change et se déplace sur cette même référence. Le HEAD change à chaque fois qu'on change de branche et à chaque commit. Le HEAD pointe vers le commit sur lequel on est en train de
travailler (la référence est sauvegardée dans le fichier .git/HEAD).
Partons d’un projet root vide initialisé depuis un serveur GIT (arma) :
Ensuite, on
se connecte sur une autre machine (
larbo) afin de faire un checkout (clone dans
le jargon de GIT) du projet root vide :
Avec la commande git branch, vous pouvez afficher les
branches. Comme indiqué sur la figure suivante, nous pouvons constater qu’il n’existe
aucune branche. En effet GIT exige un premier commit lui permettant de créer la
branche principale master. Ajoutons un nouveau fichier test.txt avec comme
contenu (git introduction : version initiale du fichier test.txt) :
Procédons au premier commit puis visualisons les objets
GIT avec la commande
git cat-file –p SHA1 :
Le HEAD pointe bien sur le commit effectué et la
référence du tree (root) du répertoire .git/objects/cc : cc6e54 ….
Visualisons les autres objets :
La visualisation du
Blob (7856be…) du fichier test.txt
nous montre bien son contenu (git introduction : version initiale du
fichier test.txt).
Deuxième commit : Ajoutons d’abord un nouveau fichier new.txt et
modifions le fichier test.txt :
Visualisons les objets :
Troisième commit :
Pour finir, ajoutons un nouveau répertoire bak et effectuons une copie
de la version initiale (version 1) du
fichier test.txt dans ce nouveau répertoire tout en modifiant la version
actuelle (version 2) du fichier test.txt pour avoir une v3. Le fichier new.txt
reste inchangé :
Les objets GIT :
Remarquons juste que le
HEAD pointe bien sur le dernier commit :